
기반 문서 : https://medium.com/google-cloud/hello-world-on-gcp-ml-engine-cc09f506361c
$ tree .
.
├── setup.py
└── trainer
├── __init__.py
├── model.py : 학습 모델
├── task.py : job을 관리하기 위한 로직
└── input.py : 데이터 제공 |
기반 자료 : https://medium.com/google-cloud/hello-world-on-gcp-ml-engine-cc09f506361c
코드 : https://github.com/jgensler8/gcp-minimal-ml-engine-project
google에 로그인
https://console.cloud.google.com/ 열기
우측 상단의 'Activate Cloud Shell' 클릭

$ git clone https://github.com/jgensler8/gcp-minimal-ml-engine-project Cloning into 'gcp-minimal-ml-engine-project'... remote: Enumerating objects: 12, done. remote: Total 12 (delta 0), reused 0 (delta 0), pack-reused 12 Unpacking objects: 100% (12/12), done. $ cd gcp-minimal-ml-engine-project/ |
trainer/task.py
# print "job_dir: {}".format(ARGS.job_dir)
print("job_dir: {}".format(ARGS.job_dir)) |
setup.py
#REQUIRED_PACKAGES = ['tensorflow>=1.8.0'] REQUIRED_PACKAGES = ['tensorflow==1.15.0'] |
trainer/task.py
#import model #import input #import tuil import trainer.model as model import trainer.input as input import trainer.util as util |
$ cd gcp-minimal-ml-engine-project/ $ make install |
$ make train_local |
GCP console에서 만듬.
본 문서에서는 'tftraining1234"
Makefile 파일 수정
#BUCKET_NAME=tftraining BUCKET_NAME=tftraining1234 |
$ make train_job |
상태 확인
state: PREPARING
trainingInput:
args:
- --train-files
- ./train
- --eval-files
- ./eval
jobDir: gs://tftraining1234/tftraining1234_2 packageUris:
- gs://tftraining1234/tftraining1234_2/packages/46ee892af3a209f2b7819ee630faf7e8a8a76f3e9c1bed5216c1d1d6073bd835/hello-world-0.1.tar.gz
pythonModule: trainer.task
region: us-central1
runtimeVersion: '1.5'
trainingOutput: {}
View job in the Cloud Console at:
https://console.cloud.google.com/mlengine/jobs/tftraining1234_2?project=slipp-study-256111
View logs at:
https://console.cloud.google.com/logs?resource=ml.googleapis.com%2Fjob_id%2Ftftraining1234_2&project=slipp-study-256111 |
from : https://medium.com/google-cloud/hello-world-on-gcp-ml-engine-cc09f506361c
$ tree .
.
├── Makefile : make의 설정 파일
├── eval : 평가 데이터
├── output
├── setup.py : python 프로젝트 셋업 설정
├── train : 학습 데이터
└── trainer
├── __init__.py
├── model.py : 모델
├── task.py : GCP ML의 작업 로직
└── input.py : 데이터 제공 로직 |
VIRTUALENV_DIR=./env
PIP=${VIRTUALENV_DIR}/bin/pip
ACTIVATE=source ${VIRTUALENV_DIR}/bin/activate
# Python + Environment
virtualenv:
virtualenv ${VIRTUALENV_DIR}
install: virtualenv
${PIP} install -e .
# TensorFlow
MODEL_DIR=./output
TRAIN_DATA=./train
EVAL_DATA=./eval
TRAINER_PACKAGE=trainer
TRAINER_MAIN=${TRAINER_PACKAGE}.task
train_local:
bash -c '${ACTIVATE} && gcloud ml-engine local train \
--module-name ${TRAINER_MAIN} \
--package-path ${TRAINER_PACKAGE} \
--job-dir ${MODEL_DIR} \
-- \
--train-files ${TRAIN_DATA} \
--eval-files ${EVAL_DATA}'
# --train-steps 1000 \
# --eval-steps 100'
#BUCKET_NAME=tftraining
BUCKET_NAME=tftraining1234
upload_train_eval_data:
echo "would upload training data"
echo gsutil cp ${TRAIN_DATA} gs://${BUCKET_NAME}/train
echo gsutil cp ${EVAL_DATA} gs://${BUCKET_NAME}/eval
# JOB_NAME=${BUCKET_NAME}_$(shell date +%s)
JOB_NAME=${BUCKET_NAME}_2
BUCKET_JOB_DIR=gs://${BUCKET_NAME}/${JOB_NAME}
REGION=us-central1
RUNTIME_VERSION=1.5
train_job:
gcloud ml-engine jobs submit training ${JOB_NAME} \
--job-dir ${BUCKET_JOB_DIR} \
--runtime-version ${RUNTIME_VERSION} \
--module-name ${TRAINER_MAIN} \
--package-path ${TRAINER_PACKAGE} \
--region ${REGION} \
-- \
--train-files ${TRAIN_DATA} \
--eval-files ${EVAL_DATA}
MODEL_NAME=helloworld_model
create_model:
gcloud ml-engine models create ${MODEL_NAME} --regions=${REGION}
MODEL_BINARIES=gs://${BUCKET_NAME}/${JOB_NAME}/export/estimator/1529119938
MODEL_VERSION=v1
create_model_version:
gcloud ml-engine versions create ${MODEL_VERSION} \
--model ${MODEL_NAME} \
--origin ${MODEL_BINARIES} \
--runtime-version ${RUNTIME_VERSION}
JSON_INSTANCES=./json_instances.jsonl
test_model_version:
gcloud ml-engine predict \
--model ${MODEL_NAME} \
--version ${MODEL_VERSION} \
--json-instances ${JSON_INSTANCES} |
import tensorflow as tf
def train_input_fn():
return tf.constant([ [[1],[1]], [[1], [2]] ]), [1]
def eval_input_fn():
return [2, 3], [1] |
2개의 함수 train_input_fn()과 eval_input_fn()을 구현한다.
어디서 데이터를 읽고 오는 지는 무관하다.
import tensorflow as tf
from tensorflow.python.framework import ops
def cnn_model_fn(features, labels, mode):
# features = Tensor("Const:0", shape=(2, 2, 1), dtype=int32, device=/device:CPU:0)
# lables = Tensor("Const_2:0", shape=(1,), dtype=int32)
# mode = "train"
input_layer = tf.constant([[1.0]])
labels = tf.constant([0])
dense = tf.layers.dense(inputs=input_layer, units=1, activation=tf.nn.relu)
dropout = tf.layers.dropout(...)
logits = tf.layers.dense(inputs=dropout, units=2)
predictions = {
"classes": tf.argmax(input=logits, axis=1),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, predictions=predictions, train_op=train_op, ...)
})
def estimator(config):
return tf.estimator.Estimator(model_fn=cnn_model_fn, config=config) |
estimator()를 구현하여야 하고 tf.estimator.Estimator()를 반환한다.
def estimator(config):
return tf.estimator.Estimator(model_fn=cnn_model_fn, config=config) |
def main():
ARGS = args_parser.parse_args()
config = util.config(ARGS.job_dir)
# config = tf.estimator.RunConfig(
# tf_random_seed=19830610,
# log_step_count_steps=1000,
# save_checkpoints_secs=120, # change if you want to change frequency of saving checkpoints
# keep_checkpoint_max=3,
# model_dir=job_dir
# )
estimator = model.estimator(config)
train_spec = tf.estimator.TrainSpec(
input.train_input_fn,
max_steps=100
)
exporter = tf.estimator.FinalExporter(
'estimator',
input.json_serving_function,
as_text=False # change to true if you want to export the model as readable text
)
eval_spec = tf.estimator.EvalSpec(
input.eval_input_fn,
exporters=[exporter],
name='estimator-eval',
steps=100
)
tf.estimator.train_and_evaluate(
estimator,
train_spec,
eval_spec
)
args_parser = argparse.ArgumentParser()
args_parser.add_argument(
'--job-dir',
help='GCS location to write checkpoints and export models',
required=True
)
args_parser.add_argument(
'--train-files',
help='GCS or local paths to training data',
nargs='+',
required=True
)
args_parser.add_argument(
'--eval-files',
help='GCS or local paths to evaluation data',
nargs='+',
required=True
)
if __name__ == '__main__':
main() |
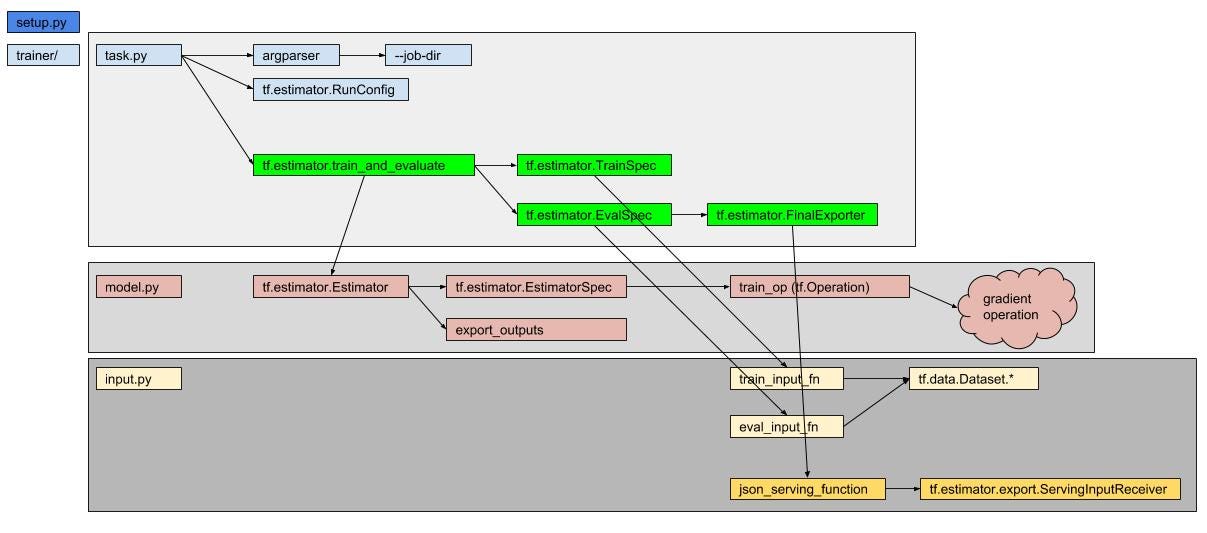
task.py는 tf.estimator.train_and_evalute()호출이 핵심이다.
tf.estimator.train_and_evaluate(
estimator, # 학습 중의 기타 설정들. 모델 저장 위치, 저장 주기, 저장 최대 수, ...
train_spec, # 학습 관련 설정들. 데이터 제공 함수, 최대 학습 수, ...
eval_spec # 검증 관련 설정들. 데이터 제공 함수, ...
) |